Kraken, the unknown Python OCR system
Kraken is a relatively unknown turn-key OCR system. However it has many benefits. In this article we discuss binarizing images for OCR'ing.
Kraken, a clone of the Ocropy, uses a neural network to recognize text. It has several nice features that are very useful if you’re trying to recognize text in images! One of those is preprocessing images before handing them to an OCR system like Kraken or Tesseract.
Binarizing images
Most OCR systems need binary images (black an white) as input. Stackoverflow is full of articles, about preprocessing images for OCR'ing. Most of the time the articles mention Fred’s Textcleaner script. This is a bash script performing various ImageMagick actions to output a binary image.
Kraken comes with an ‘nlbin’ algorithm that performs very good. It is similar to ocropus-nlbin. It is very easy to install. Simply run:
pip install kraken
Next to binarize an image use:
kraken -i input.jpg output.png binarize
Without any parameter tweaking it turns the images used in above’s Stackoverflow links into:
Example 1
Original
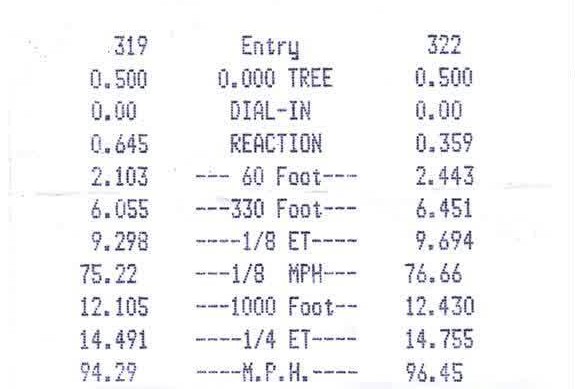
Binarized
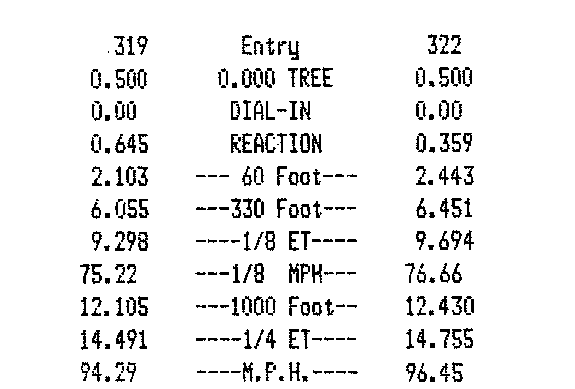
Example 2
Original

Binarized

Photo example
Even in plain photo’s like the one below the algorithm comes up with a nice result.
Original
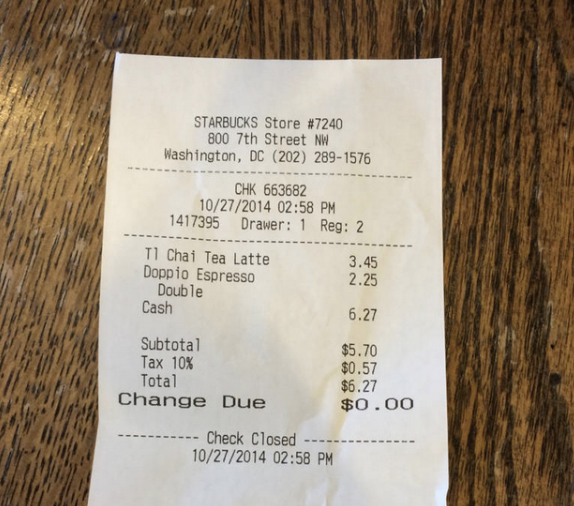
Binarized

Training vs Tesseract
Another great benefit of Kraken is that training is easy (or at least easier than training Tesseract). More on this in a future post.